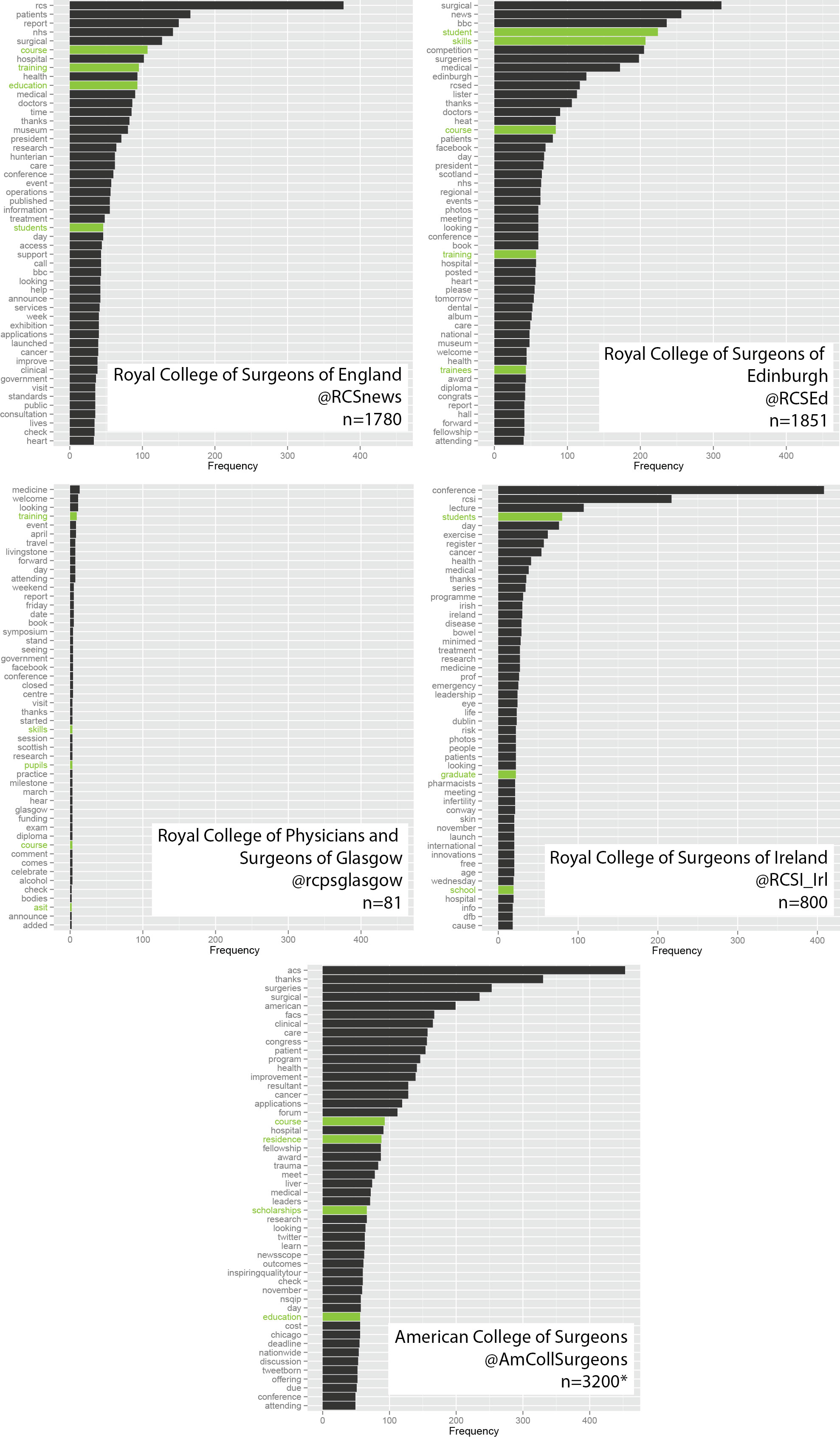
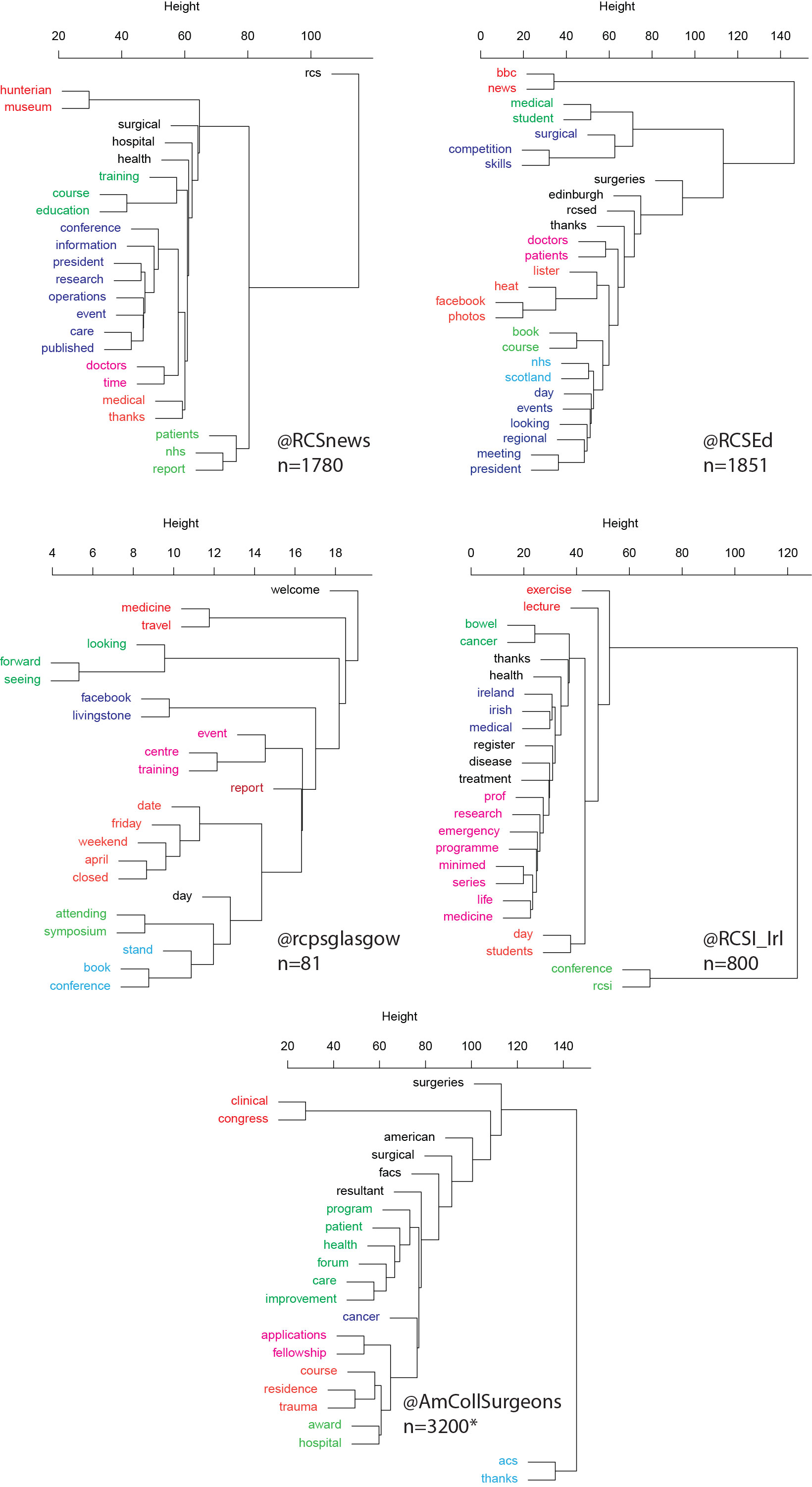
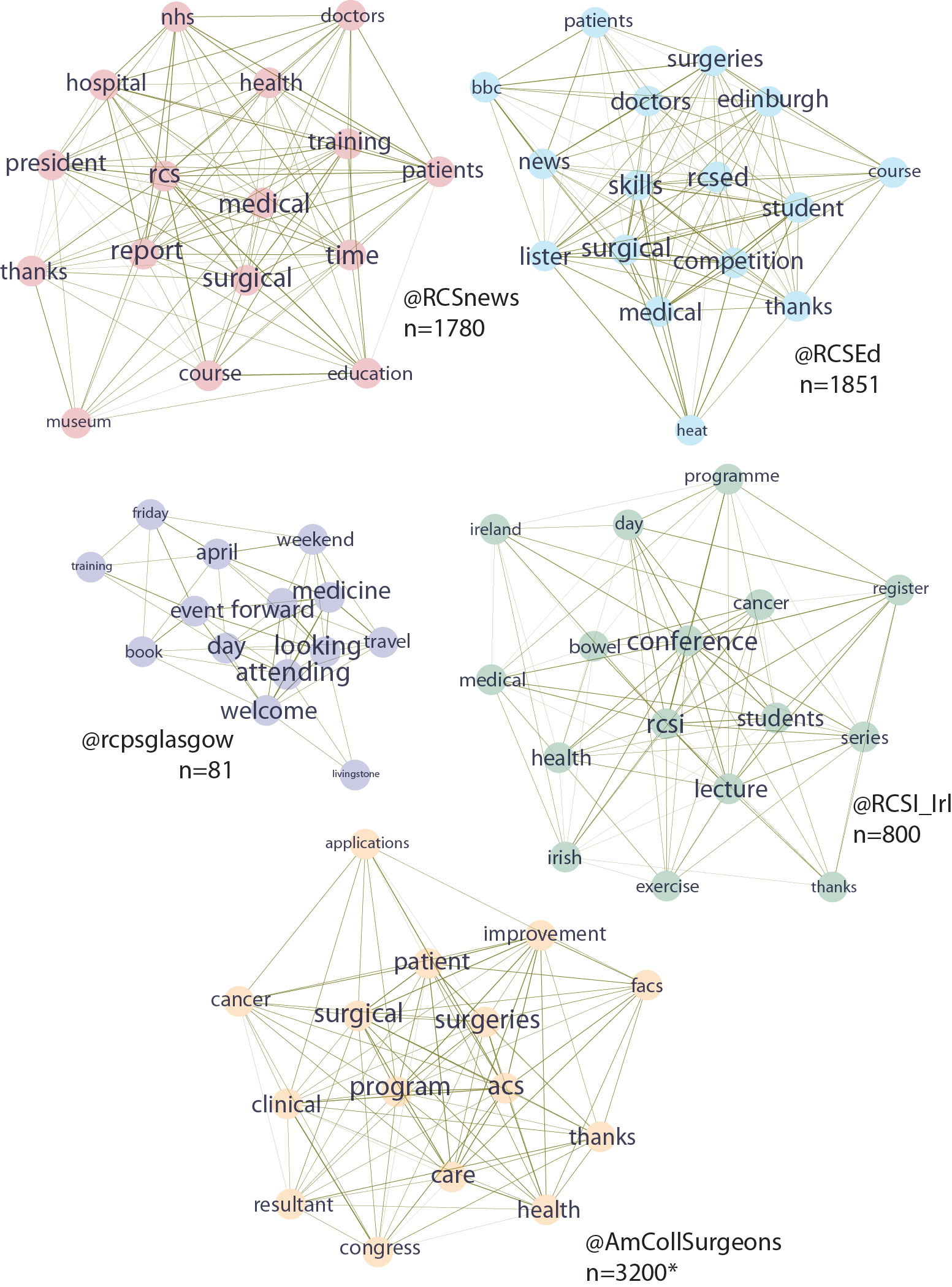
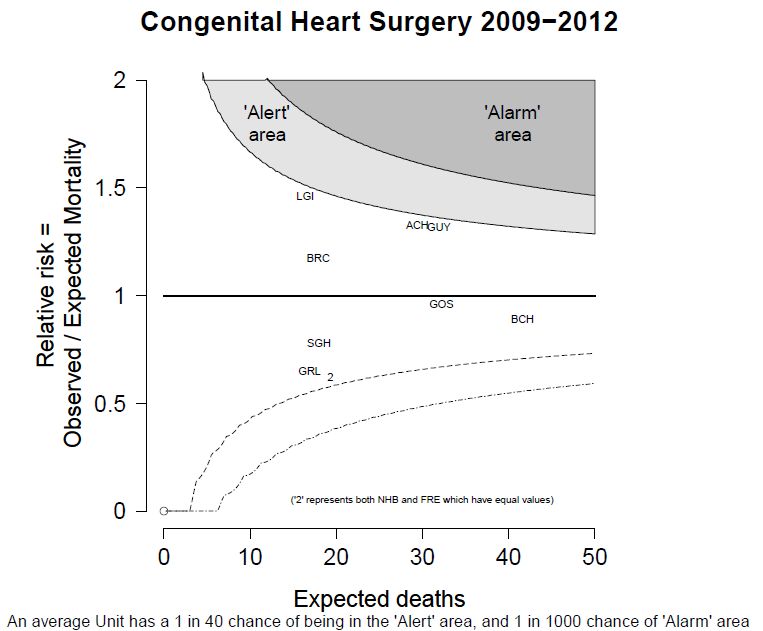
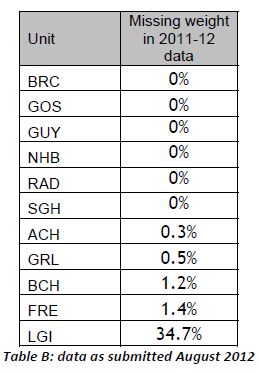
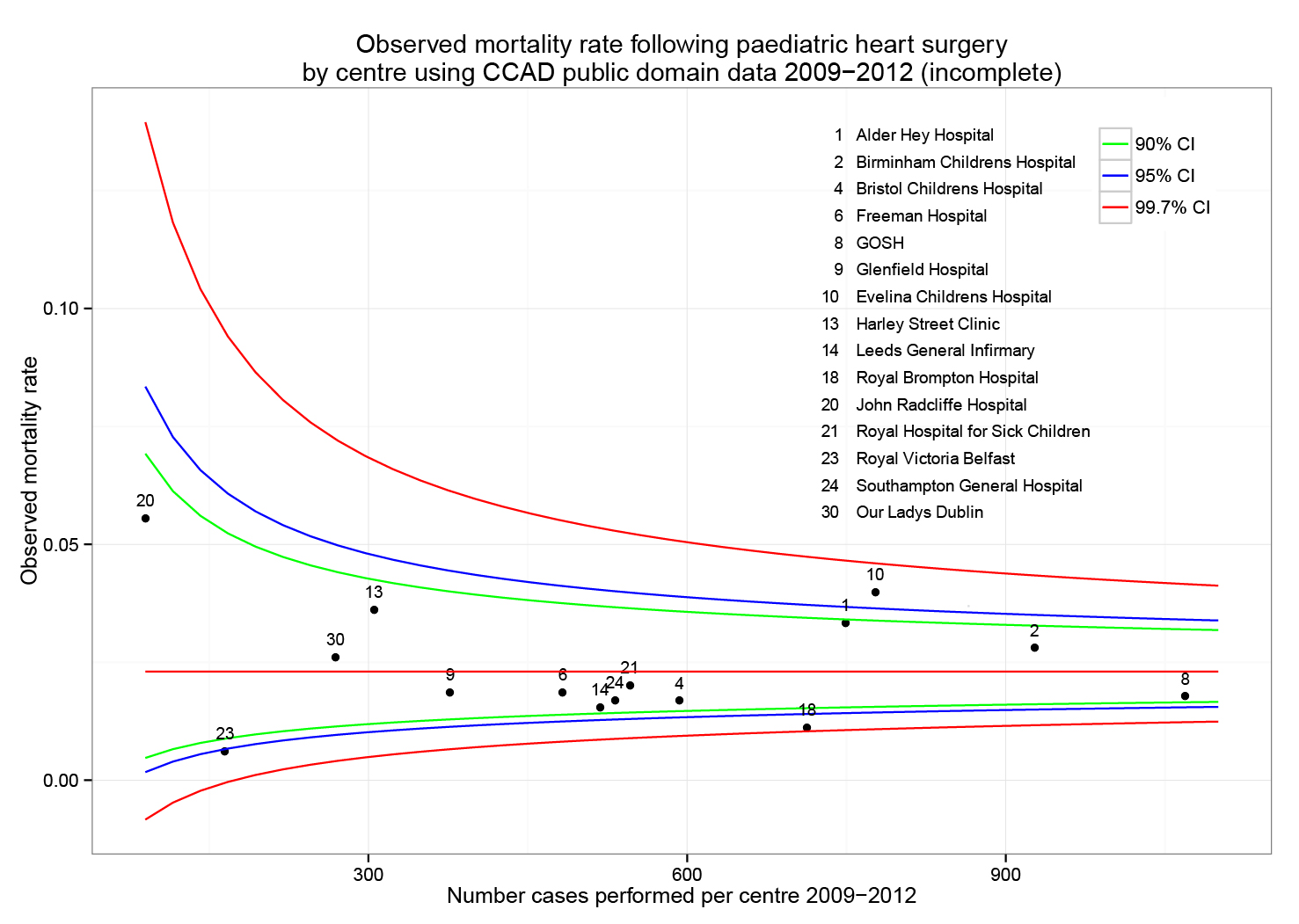
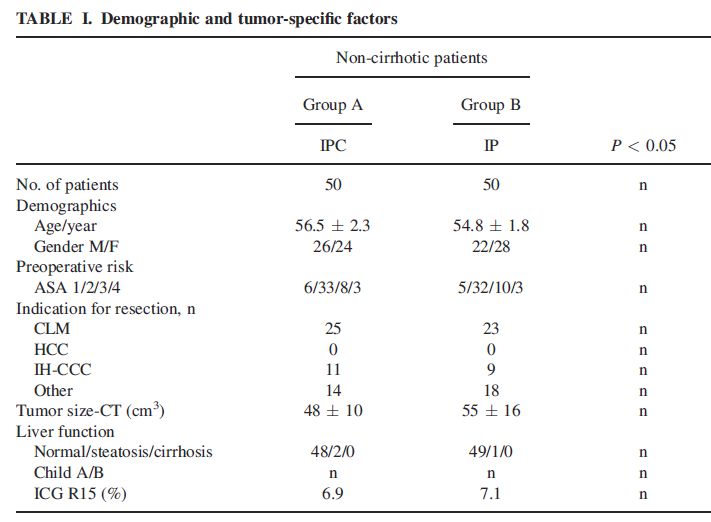
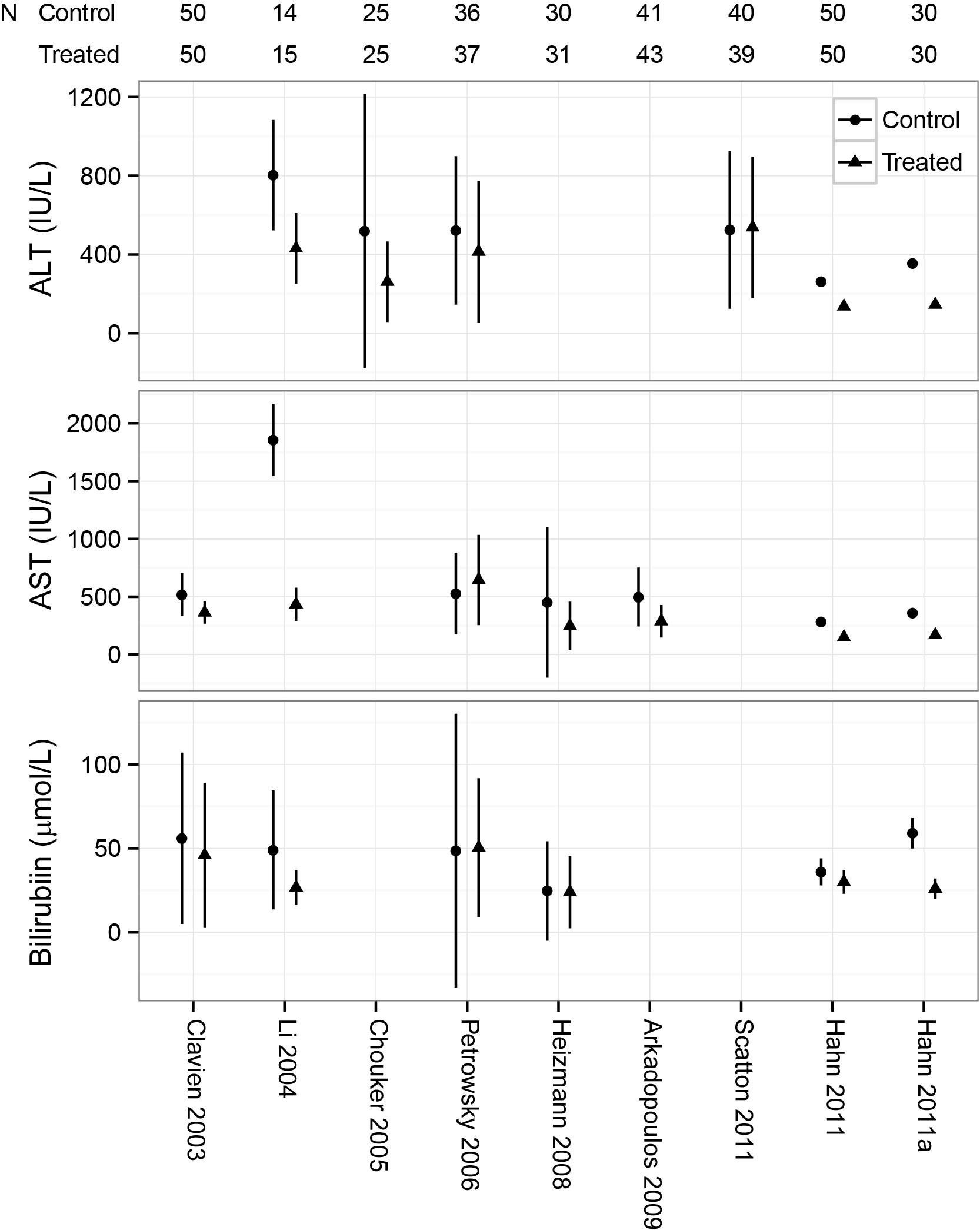
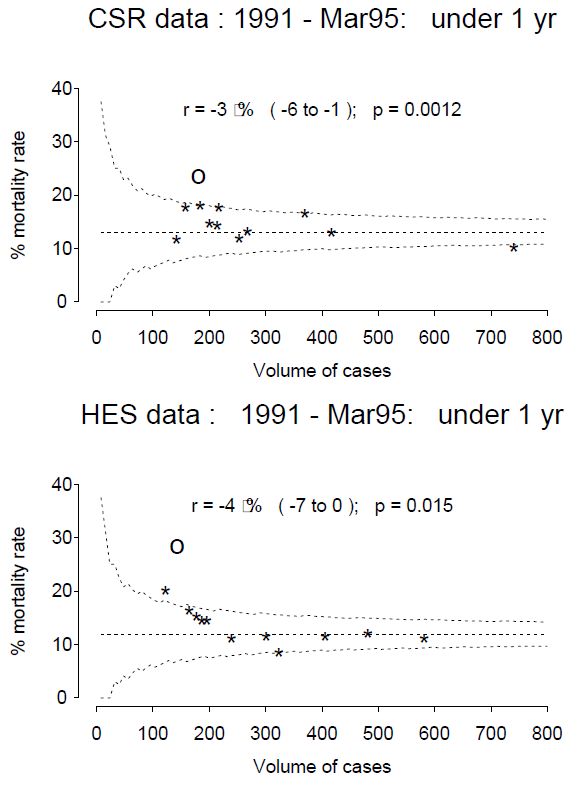
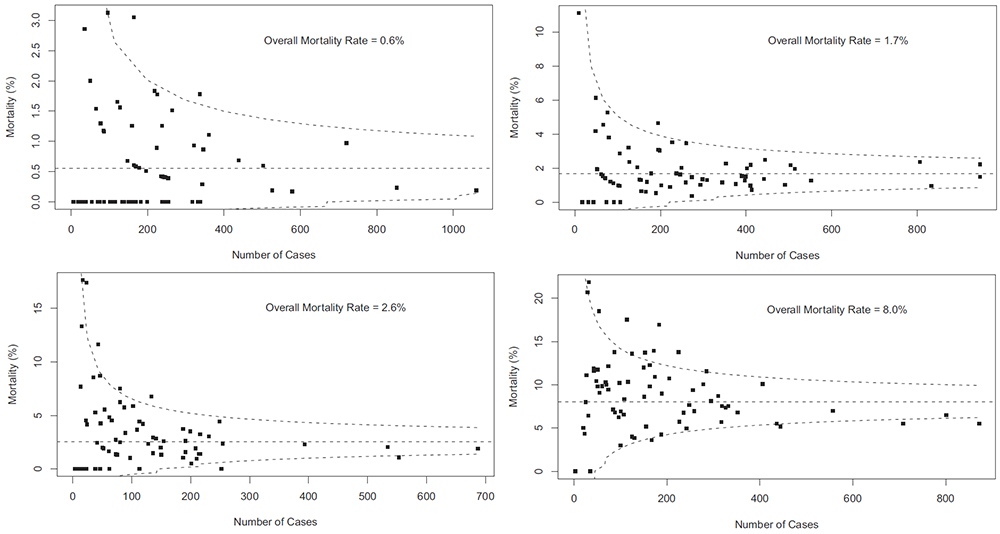
This is useful number if you have hundreds of PMIDs and need specific fields from the pubmed/medline citation.
#################################
# Retrieve pubmed citation data #
# Ewen Harrison #
# March 2013 #
# www.datasurg.net #
#################################
# Sample data
pmid<-c(8339401,8485120,8427851,3418853,3195585,2643302,7947591,8274474,8243847)
#-----------------------------------------------------------------------------------------------------------------------------------
# Batch list of PMIDs into groups of 200
fn_batch<-function(pmid=pmid,n=200){
require(plyr)
b<-list()
max=ceiling(length(pmid)/n)
for (i in 1:max){
b[[i]]<-pmid[(1+((i-1)*n)):(n*i)]
}
b[[max]]<-b[[max]][!is.na(b[[max]])] # drop missing values in the final block
c<-llply(b, function(a){ # convert from list to comma separted list
paste(a, collapse=",")
})
return(c)
}
#-----------------------------------------------------------------------------------------------------------------------------------
# Run
pmid_batch<-fn_batch(pmid)
#-----------------------------------------------------------------------------------------------------------------------------------
# Function to fetch, parse and extract medline citation data. Use wrapper below.
get_pubmed<-function(f){
require(RCurl)
require(XML)
require(plyr)
# Post PMID (UID) numbers
url<-paste("http://eutils.ncbi.nlm.nih.gov/entrez/eutils/efetch.fcgi?db=pubmed&id=", f, "&retmode=XML", sep="")
# Medline fetch
g<-llply(url, .progress = progress_tk(label="Fetching and parse Pubmed records ..."), function(x){
xmlTreeParse(x, useInternalNodes=TRUE)
})
# Using given format and xml tree structure, paste here the specific fields you wish to extract
k<-ldply(g, .progress = progress_tk(label="Creating dataframe ..."), function(x){
a<-getNodeSet(x, "/PubmedArticleSet/*/MedlineCitation")
pmid_l<-sapply (a, function(a) xpathSApply(a, "./PMID", xmlValue))
pmid<-lapply(pmid_l, function(x) ifelse(class(x)=="list" | class(x)=="NULL", NA, x))
nct_id_l<-sapply (a, function(a) xpathSApply(a, "./Article/DataBankList/DataBank/AccessionNumberList/AccessionNumber", xmlValue))
nct_id<-lapply(nct_id_l, function(x) ifelse(class(x)=="list" | class(x)=="NULL", NA, x))
year_l<-sapply (a, function(a) xpathSApply(a, "./Article/Journal/JournalIssue/PubDate/Year", xmlValue))
year<-lapply(year_l, function(x) ifelse(class(x)=="list" | class(x)=="NULL", NA, x))
month_l<-sapply (a, function(a) xpathSApply(a, "./Article/Journal/JournalIssue/PubDate/Month", xmlValue))
month<-lapply(month_l, function(x) ifelse(class(x)=="list" | class(x)=="NULL", NA, x))
day_l<-sapply (a, function(a) xpathSApply(a, "./Article/Journal/JournalIssue/PubDate/Day", xmlValue))
day<-lapply(day_l, function(x) ifelse(class(x)=="list" | class(x)=="NULL", NA, x))
year1_l<-sapply (a, function(a) xpathSApply(a, "./Article/ArticleDate/Year", xmlValue))
year1<-lapply(year1_l, function(x) ifelse(class(x)=="list" | class(x)=="NULL", NA, x))
month1_l<-sapply (a, function(a) xpathSApply(a, "./Article/ArticleDate/Month", xmlValue))
month1<-lapply(month1_l, function(x) ifelse(class(x)=="list" | class(x)=="NULL", NA, x))
day1_l<-sapply (a, function(a) xpathSApply(a, "./Article/ArticleDate/Day", xmlValue))
day1<-lapply(day1_l, function(x) ifelse(class(x)=="list" | class(x)=="NULL", NA, x))
medlinedate_l<-sapply (a, function(a) xpathSApply(a, "./Article/Journal/JournalIssue/PubDate/MedlineDate", xmlValue))
medlinedate<-lapply(medlinedate_l, function(x) ifelse(class(x)=="list" | class(x)=="NULL", NA, x))
journal_l<-sapply (a, function(a) xpathSApply(a, "./Article/Journal/Title", xmlValue))
journal<-lapply(journal_l, function(x) ifelse(class(x)=="list" | class(x)=="NULL", NA, x))
title_l<-sapply (a, function(a) xpathSApply(a, "./Article/ArticleTitle", xmlValue))
title<-lapply(title_l, function(x) ifelse(class(x)=="list" | class(x)=="NULL", NA, x))
author_l<-sapply (a, function(a) xpathSApply(a, "./Article/AuthorList/Author[1]/LastName", xmlValue))
author<-lapply(author_l, function(x) ifelse(class(x)=="list" | class(x)=="NULL", NA, x))
return(data.frame(nct_pm=unlist(nct_id), pmid=unlist(pmid), year=unlist(year), month=unlist(month), day=unlist(day),
year1=unlist(year1), month1=unlist(month1), day1=unlist(day1), medlinedate=unlist(medlinedate), journal=unlist(journal),
title=unlist(title), author=unlist(author) ))
})
}
#-----------------------------------------------------------------------------------------------------------------------------------
# Wrapper function uses batched PMID list and get_pubmed to run pubmed search
# Path takes desired name for folder to save data frames referred to as data files.
fn_pubmed<-function(pmid = pmid_batch, path="pmid_data", from=1, to=max){
require(plyr)
max<-length(pmid)
if (file.exists(path)==FALSE){
dir.create(path)
}
for (i in from:to){
df<-data.frame()
df<-get_pubmed(pmid[[i]])
file<-paste(path, "/data", i,".txt", sep="")
write.table(df, file=file, sep=";")
}
}
#-----------------------------------------------------------------------------------------------------------------------------------
fn_pubmed(pmid_batch)
#-----------------------------------------------------------------------------------------------------------------------------------
# Merge back saved tables
fn_merge<-function(path="pmid_data"){
require(plyr)
data_files<-list.files(path, full.names=T)
df<-ldply(data_files, function(x){
df1<-read.csv(x, header=TRUE, sep=";")
df2<-data.frame(data_files=gsub(pattern=paste(path, "/", sep=""), replacement="",x), df1)
return(df2)
})
return(df)
}
#-----------------------------------------------------------------------------------------------------------------------------------
# Run
data<-fn_merge()